The last couple years have seen me dabbling in daily fantasy sports (dfs) - mostly in basketball, since it's my favorite sport, but a little bit of football as well. My experience playing in a few daily fantasy contests on Fanduel and DraftKings exposed me to just how competitive and lucrative this industry really is. There are a frequent number of contests with thousands upon thousands of participants, with cash prizes that can exceed hundreds of thousands of dollars - for a single contest! Initially I realized that it was incredibly hard to casually pick a lineup of players purely based on your "intuition"; very rarely would you be able to win money this way. You need to develop some type of predictive framework that can help you collect data on different players, and make predictions about how they will perform, based on various metrics. This post is part 1 in a series that focuses on creating a software framework for daily fantasy basketball, but the basic framework and methodology can be modified and extended for other sports as well.
In this first post, I will discuss how to scrape ESPN's website for NBA player data, and create an Excel spreadsheet of all the box score statistics for each game in which that player was active. ESPN has a page for each team in the NBA which lists all the players on that particular team's roster. The url for the ESPN player page is located at http://www.espn.com/nba/players.
Let's go ahead and use my favorite team - the Golden State Warriors - as our example for this exercise. Below is the code that will enable us to scrape the team roster page and extract the url for whichever team's roster we want to access.
class Team:
'Common base class for all NBA teams'
team_count = 0
def __init__(self, team_name, team_link):
self.team_name = team_name
self.team_link = team_link
self.player_links = []
self.player_names = []
self.player_positions = []
self.game_log_links = []
self.team_links = {}
self.player_list = []
Team.team_count += 1
def get_players(self):
# add wait times in between getting each team's data to prevent overload
wait_time = round(max(5, 10 + random.gauss(0,3)), 2)
time.sleep(wait_time)
self.team_page = urlopen(self.team_link)
self.soup = BeautifulSoup(self.team_page, 'html.parser')
for a in self.soup.findAll('a'):
if '/player/' in a['href']:
self.player_links.append(a['href'])
#extract the name of each player
for a in self.soup.findAll('td', attrs={'class': 'sortcell'}):
for b in a.findAll('a'):
self.player_names.append(b.text)
for i in range(0, len(self.player_links)):
game_log_link = str.replace(self.player_links[i], '/_/', '/gamelog/_/')
game_log_link = str.replace(game_log_link, self.player_names[i], 'year/' + self.year + '/' + self.player_names[i])
self.game_log_links.append(game_log_link)
#now we have links to all the player URLs for this particular team
for i in range(0, len(self.player_links)):
new_player = Player(self.team_name, self.player_names[i], self.player_links[i], self.game_log_links[i])
new_player.get_season_stats()
if new_player.active == False:
continue
new_player.get_each_game_stats()
self.player_list.append(new_player)
return self.player_listThere's a good bit of code here, so let's examine it step by step. First, we create a Team class
which will serve as the common base class for each NBA team. We initialize our team with a team_name
and team_link, and initialize a bunch of empty lists to store subsequent data that we need to crawl.
self.player_links: links to each player page url (covered in next section)self.player_names: the name of each player (pretty self explanatory)self.player_positions: the position that each player plays (PG, SG, SF, PF, C)self.game_log_links: the urls for each player's game logself.player_list: a list of all the player objects for this particular team
The get_players method starts off with introducing random wait times so as to not overload the
web page, followed by opening the team url using urlopen and creating the BeautifulSoup
object from the resulting self.team_page object. Let's go ahead and use my favorite team - the
Golden State Warriors - as our example for this exercise. Clicking on the link for this team will take us to
the team roster page, as shown below.
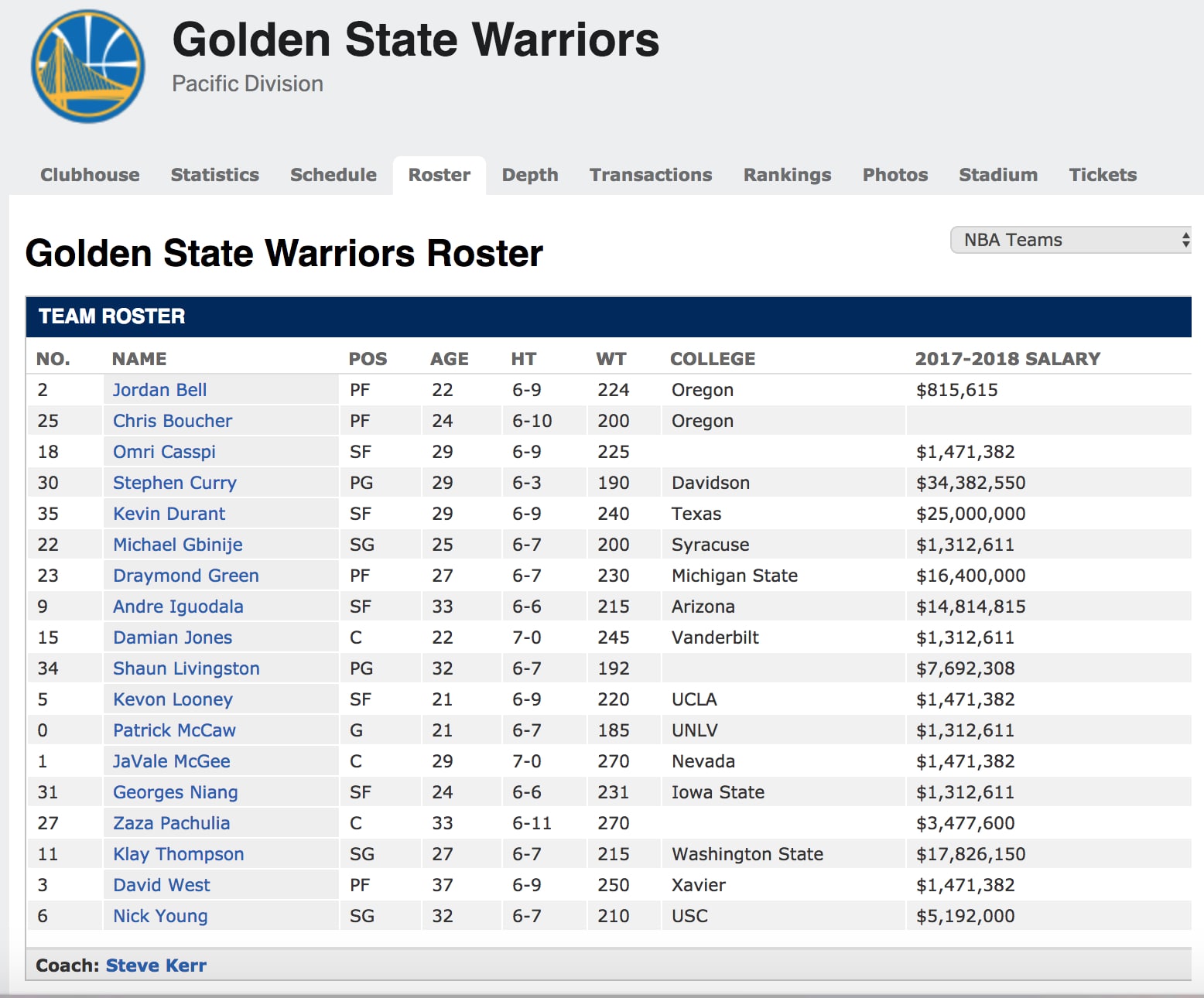
Then, we use the standard findAll method to loop through the resulting HTML and grab all the player page links,
specified by an tag that contains /player/ in the url. Once we grab all these, we store them
in self.player_links. The next loop iterates through self.player_links, going to each player's web page
and grabbing the player's game log url. Let's use my favorite player -
Stephen Curry - as an example to emulate what this code is doing.
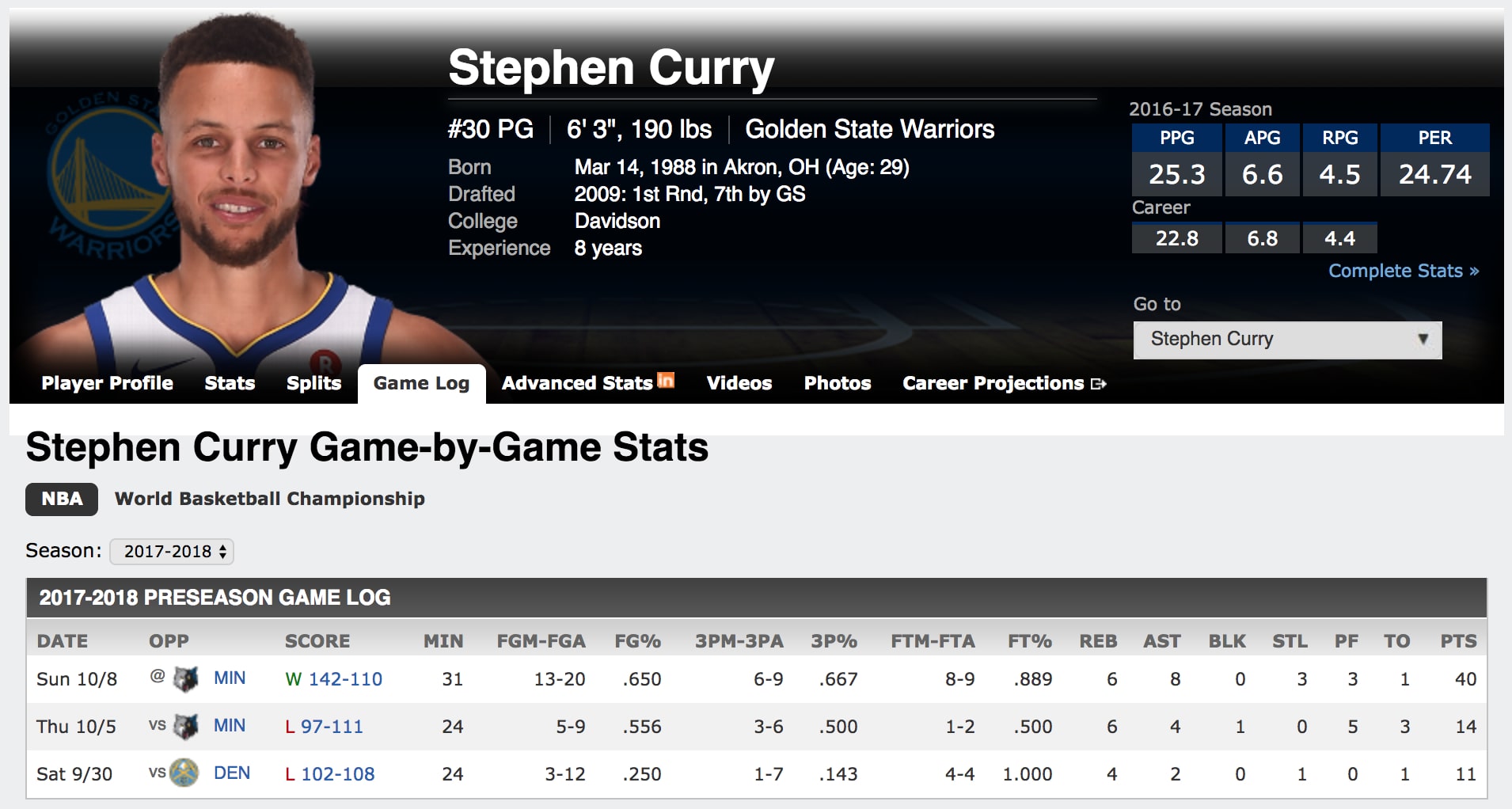
The player page contains multiple tabs, but the tab we are interested in for this exercise is the game log tab. However, since the season hasn't started yet, there are only a few preseason games listed for this year. Let's go ahead and click on the drop-down menu for the season and select 2016-2017 instead, so we can see the box score stats for all of last year.
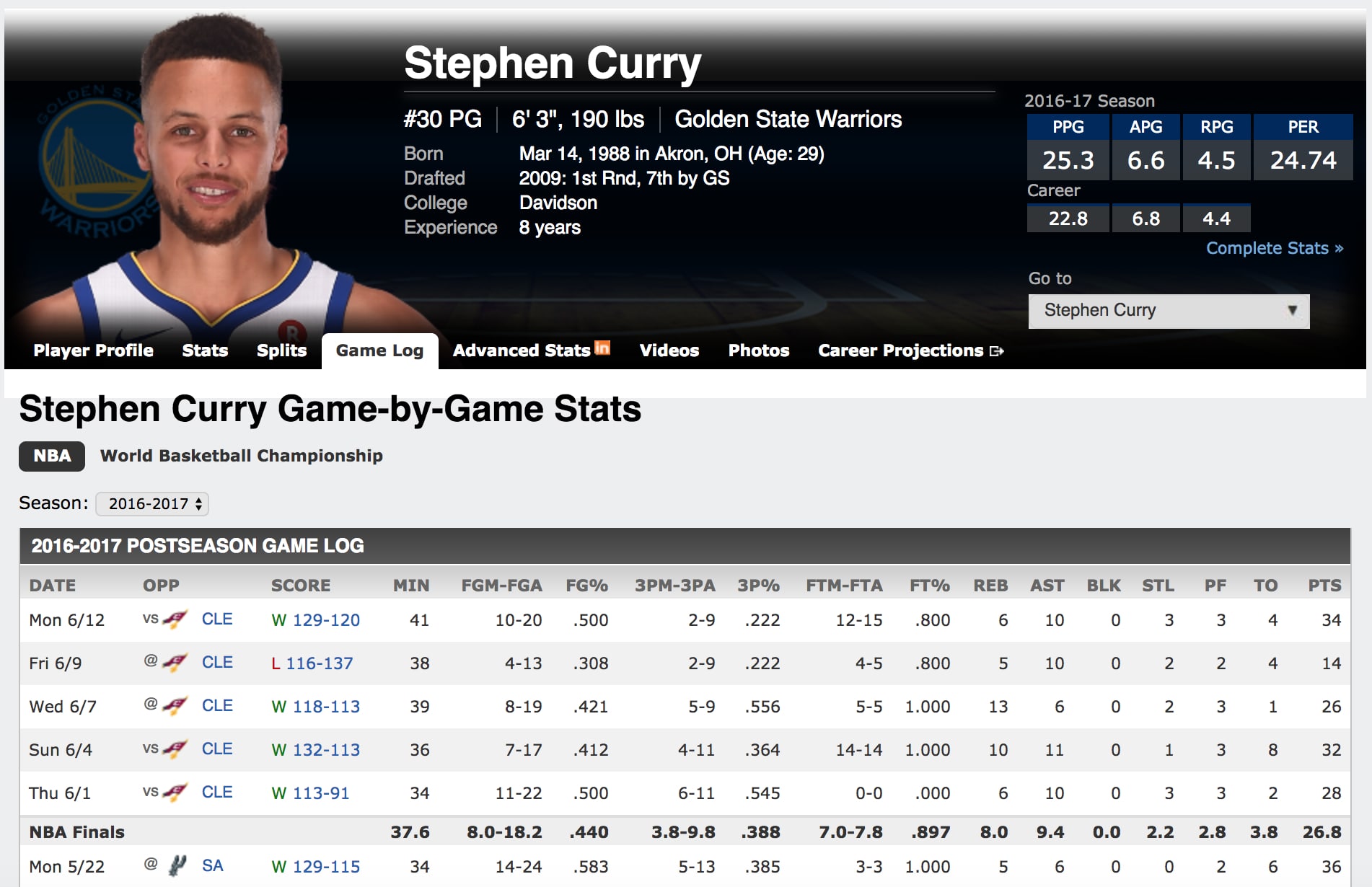
If we take a look at a updated url after selecting the 2016-2017 season, we can see that /2017/ is added to the url in betweenyear
and stephen-curry. Therefore, we add this to the url before storing it in self.game_log_links. We'll look at collecting the box score
statistics a little bit later; for now let's jump back to the team roster page. In the next loop, we collect the names of each player, stored in the a href
tags that link to each player page. Then we append these to self.player_names.
In the final loop of get_players, we cycle through self.player_links, and create a new Player
object for each player on the team. We'll take a look at the details of the Player object definition below. As you can see, we are calling the method
get_season_stats() belonging to the Player object, which extracts the player's average season statistics. Then, we check to see if that
particular player is active or not; if he isn't, then we don't need to collect stats for him. If the player is active, then we continue collecting the individual
game box score statistics for each game played within that season, using get_each_game_stats(). Finally, we append the newly created
Player object to self.player_list. I'll end this post right here, and in my next post we'll take a look at the Player class
definition to see how we actually extract the data.