In my previous post, I described how to create data structures for scraping stock market data from the web, using Barron's as an example. Since the data we wanted to scrape from Barron's website was fully rendered in HTML, we could simply use BeautifulSoup on its own to extract the required content. However, BeautifulSoup alone will not work if the content is embedded in JavaScript. For this we need to use PhantomJS and Selenium.
My primary motivation for this tutorial is that the documentation for Selenium and PhantomJS is quite convoluted, making a seemingly basic JavaScript scraping task seem complicated and non-intuitive. Once I was able to figure it out, however, I envisioned creating a sort of step-by-step "cheat sheet" that would enable others to pick this up relatively quickly, without having to bury themselves in a web of countless Google and Stack Overflow searches like I did. Before we begin, first install Selenium and PhantomJS from your terminal, using Brew:
$ pip install selenium
$ brew install phantomjsNow that we have our required utilities set up, we need to inspect the HTML source code for the
JavaScript-rendered site that we want to scrape. If you just try to view the source, you will only see the
JavaScript sections added under the script tag. We need to inspect the source in order to see
the JavaScript executed and loaded as HTML. Then we must navigate through the web of nested HTML tags in order
to find the content we are looking for. The resulting HTML after JavaScript content is loaded is usually quite
complex and intricate, much more so than a bare-bones HTML webpage (this makes intuitive sense, since JavaScript
handles more complex tasks than those which can be done by HTML alone).
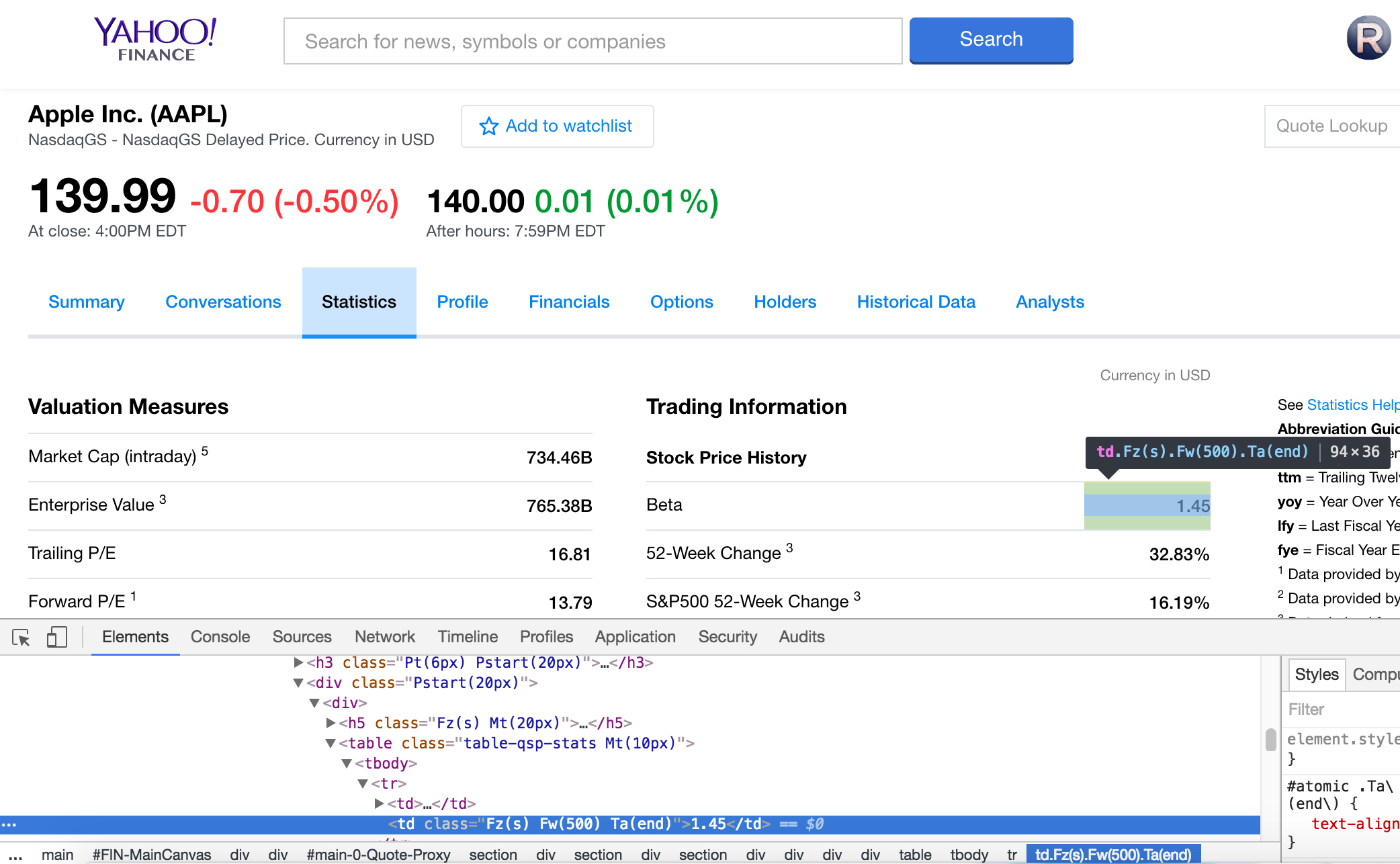
Running your cursor over different sections of the webpage will highlight the sections of code that correspond to it. Let's try to navigate our way to where the value for "Beta" is contained. Don't worry too much about the strange tag id's; we're only concerned with finding the specific tags that we need. For now, we'll focus on just grabbing this one piece of information - the stock's beta value - to demonstrate the power of Selenium and PhantomJS. Afterwards, you can extrapolate it to whatever content you want to scrape. In order to obtain the element that we want, the easiest way is to use the XPath for that element. Right-click the line of code corresponding to your desired element, select "Copy", and then select "Copy XPath". This will copy the XPath variable to the clipboard, which we can then use in our Python script. I would suggest pasting the XPath in a safe place, perhaps a simple text file, so that you can retrieve it later.

Now we can start writing our scraper. Unlike my last post, which contained more complex data structures, here we'll just define
one StockQuote class to illustrate the power of Selenium and PhantomJS.
class StockQuote:
def __init__(self, symbol, company):
self.symbol = symbol
self.company = company
def scrape_yahoo(self, div=0):
# Start with Yahoo's base URL format and use string replace for our current stock symbol
url = 'http://finance.yahoo.com/quote/%s/key-statistics?p=%s/' % (self.symbol, self.symbol)
# Instantiate the driver
driver = webdriver.PhantomJS()
driver.get(url)
driver.implicitly_wait(20)
# Use the XPath to get Beta value
elem = driver.find_element_by_xpath("//*[@id='main-0-Quote-Proxy']/section/div[2]/section/div/section/div[2]/div[2]/div/div[1]/table/tbody/tr[1]/td[2]")
# Store the value
self.beta = elem.textThe StockQuote class is relatively simple, with the constructor setting the self.symbol
and self.company variables to the values that are passed in. The interesting part of the code begins
with the scrape_yahoo() function. First, we need to define our url string. The Yahoo URL
that stores key statistics for a particular stock contains the stock symbol twice, which is how each URL differentiates
itself from each other. Therefore, we just use string replace to set the unique url string for each stock.
Now for the tricky part. In order to utilize PhantomJS, we need to instantiate a driver by using the base
call to webdriver.PhantomJS(). PhantomJS is essentially a headless WebKit for website testing. This means that
it essentially uses a "virtual" browser rather than actually opening up the browser interface. This enables much faster unit
tests for websites, since the overhead of browser startup and shutdown is avoided. We need to call the get()
member function belonging to driver, passing our url variable in as the main argument. Its
generally a good practice to add a specified wait time, especially if you are scraping many different URLs at once. Let's
take a closer look at the next line of code.
# Use the XPath to get Beta value
elem = driver.find_element_by_xpath("//*[@id='main-0-Quote-Proxy']/section/div[2]/section/div/section/div[2]/div[2]/div/div[1]/table/tbody/tr[1]/td[2]")We use the find_element_by_xpath() method to extract the element corresponding to a particular XPath. Take a
second to notice the way the XPath string is structured - its essentially the HTML directory tree for the element we are
scraping. This is why the last part of the XPath string is /table/tbody/tr[1]/td[2] which corresponds to the HTML source
we inspected when looking at Yahoo's website. The stock's Beta value is stored in the second td element, which is why the XPath
ends in td[2].
Once we instantiate elem to the element we are extracting, we can access its text member variable to
extract the string that is stored under that tag. We can then simply store elem.text within the StockQuote
member variable self.beta. Let's run a simple test case in our main method to see if the program correctly
scrapes the Beta value for Apple stock (ticker symbol: AAPL).
def main():
# Test out one quote to see if correct text is returned
my_quote = StockQuote('AAPL', 'Apple')
my_quote.scrape_yahoo()
print my_quote.beta
if __name__ == '__main__':
sys.exit(main())We create a new StockQuote object and name it my_quote, and call the scrape_yahoo() method.
We can run the program to see the output printed to the console:

Sure enough, the beta value printed out matches correctly with the value 1.45 listed on the Yahoo page. Hopefully you can now realize
the power of Python with Selenium and PhantomJS to scrape JavaScript-embedded content from the web, among its many other uses. You can just
follow the same steps outlined in this post for each piece of data you need to scrape. If you wanted to scrape the beta value for many different
stocks at once, for example, the corresponding XPath should be the same for each stock quote's Yahoo page. Thus, you could just put everything in
a for loop and simply make sure to change the value of url every time. Be sure to check out the
Github repository if you want to download the source code for
yourself. Thanks for reading!