Data Science Portfolio
Scrape Proxy Table with pandas
Overview
- We will use the pandas library to easily scrape the list of proxies at the following website:
- https://hidemy.name/en/proxy-list/
- The
read_html()method will be used to extract all tables from the HTML - The website looks like this:
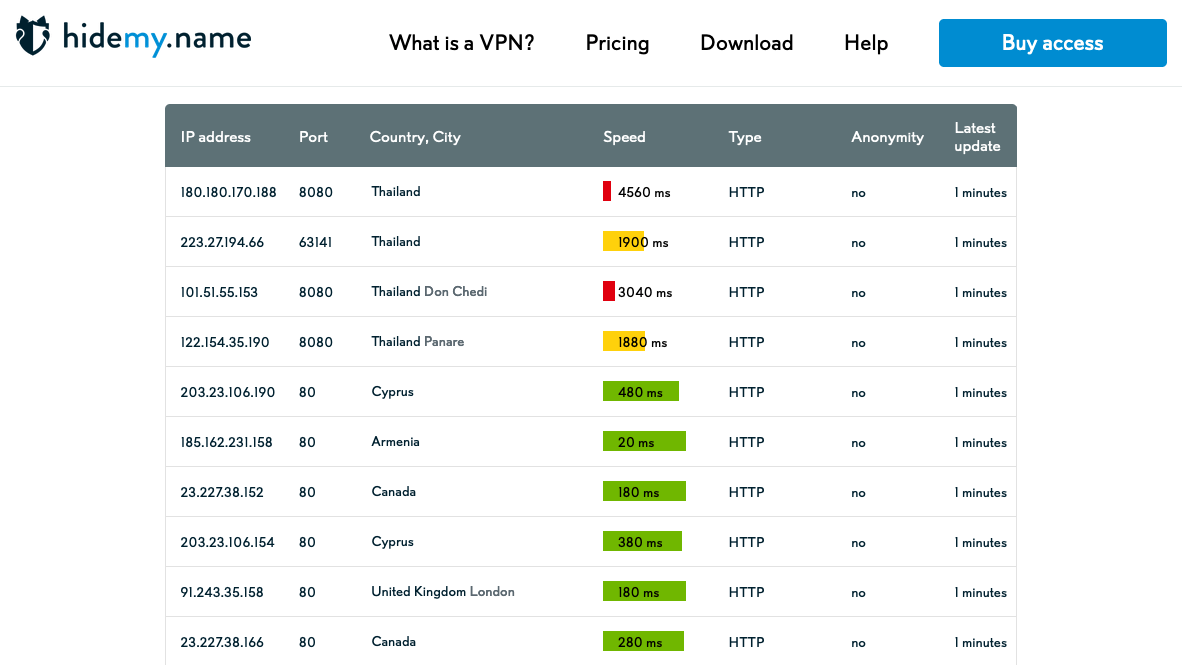
Import libraries
import requests
import pandas as pd
Set user agent header and get website response
- In order to avoid getting an HTTP Error 403 (Forbidden), we need to set a user agent header
- We can then feed this header as an argument to the
get()method from therequestslibrary
url = 'https://hidemy.name/en/proxy-list/'
header = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.75 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
r = requests.get(url, headers=header)
Get all tables from the HTML
- Now we can use
r.text(the text of the response) as our input to theread_html()method - The
read_html()method returns a list of all tables from the HTML stored in the responser
tables = pd.read_html(r.text)
print(f'Total tables: {len(tables)}')
Total tables: 1
Store proxy list table in pandas DataFrame
- Since there is only one table, our list
tableswill only contain one element - We can store the table in a pandas DataFrame
- Printing
df.head()and comparing with the screenshot above confirms that the table has been extracted successfully
df = tables[0]
df.head()
| IP address | Port | Country, City | Speed | Type | Anonymity | Latest update | |
|---|---|---|---|---|---|---|---|
| 0 | 180.180.170.188 | 8080 | Thailand | 4560 ms | HTTP | no | 41 seconds |
| 1 | 223.27.194.66 | 63141 | Thailand | 1900 ms | HTTP | no | 43 seconds |
| 2 | 101.51.55.153 | 8080 | Thailand Don Chedi | 3040 ms | HTTP | no | 43 seconds |
| 3 | 122.154.35.190 | 8080 | Thailand Panare | 1880 ms | HTTP | no | 43 seconds |
| 4 | 203.23.106.190 | 80 | Cyprus | 480 ms | HTTP | no | 1 minutes |